

「SOC に ChatGPT をつなげればいいだけじゃない?」と誰かが言い、全員が同意する、そんな瞬間を目にしたことはありませんか?このブログは、その“次に何が起きるのか”についてです。
というのも、どれほど魅力的に聞こえても、SOC に 生成AI を導入するのは魔法ではありません。現実は混沌としていて、大量のデータを必要とします。そして内部で実際に何が起きているのかを測定しなければ、混乱を自動化してしまうだけになりかねません。
そこで、私たちは測定することにしました。
SOC における 生成AI:魅力的なアイデア、厳しい現実
まずはあきらかな事実から。現在、セキュリティの世界では AI が至るところで使われています。
どの SOC 向けスライドにも、「生成AI アシスタント」という表記が必ずどこかにあります。しかし、それらのアシスタントが実際の SOC ワークフローに直面したとき、どのように動作するのか、そこが本当に力量が試される時です。
そこで登場するのがすべての AI エージェントを統括する航空管制官のような存在である Vectra MCP Serverです。
これは、ChatGPT や Claude といった LLM を、セキュリティツール(そしてそのデータ)に接続します。今回のケースでは Vectra AI です。
MCP は、エンリッチメント、相関分析、封じ込め、コンテキストをオーケストレーションし、AI エージェントがダッシュボードに埋もれることなく、本当に重要なシグナルと直接やり取りできるようにします。
そして、誰もがこれらの機能を活用・体験できるよう、任意の Vectra プラットフォームを AI ワークフローに接続できる 2 種類の MCP サーバーを公開しました。
- 🖥️ QUX - オンプレミス版:http://github.com/vectra-ai-research/vectra-ai-mcp-server-qux
「LLM を自分のセキュリティスタックにつないで、何が起きるか見てみたい」と思っていたなら、今すぐ可能です。ライセンスの制約も NDA も不要で、つないで試すだけです。
Vectra AI では、生成AI と MCP の組み合わせが SOC の運用を根本的に変えると本気で考えています。
これは「いつか実現する」話ではありません。すでに起きており、Vectra AI のユーザーがこの変化を最大限活用できるよう、私たちは準備を進めています。
そのため、私たちは顧客、見込み客、パートナーと多くの時間を費やして対話しています。技術がどれほどのスピードで進化しているのか、そして実運用の SOC において「LLM 対応」とは本当に何を意味するのかを理解するためです。
そこで、私たちは測定することにしました。
生成AI がセキュリティ運用を再定義するのであれば、私たちのプラットフォーム、データ、MCP 連携がその新しい世界にシームレスに接続できることを確実にしなければなりません。有効性の測定は副次的な作業ではなく、SOC を将来に備えさせるための方法です。
重要なのは「データの量」ではなく「データの質」
率直に言います。良質なデータがない 生成AI は、目隠しをしたシャーロック・ホームズを雇うようなものです。
Vectra AI において、データこそが差別化要因です。特に重要な点は 2 つあります。
- AI ベースの検知:単なる異常ではなく、長年にわたる攻撃者の振る舞い研究に基づいて構築されています。攻撃者がツールを変えても有効性を保つよう設計されており、静的な指標ではなく意図や振る舞いに焦点を当てています。これにより、SOC チームは目にしているものが本物で、かつ関連性が高いと確信できます。
- エンリッチされたネットワークメタデータ:ハイブリッド環境全体をカバーする高コンテキストのテレメトリで、構造化・相関付けされており、機械可読かつ即座にアクション可能です。
これこそが 生成AI が本当に活用できるデータです。これを LLM に与えると、熟練アナリストのように推論し始めます。一方、生ログを与えると、DNS について非常に自信満々な幻覚を語り始めるでしょう。
AIアナリストをどう評価するのか?
単に「もっと早く悪者を見つけて」と頼むだけでは不十分です。
重要なのは「どのように考えるか」を測定することです。MCP を介した AI エージェントの場合、主に影響を与えられる要素は 3 つあります。
- モデル(GPT-5、 Claude、Deepseekなど)
- プロンプト(どのように行動するように指示するか-トーン、構成、目標)
- MCPそのもの(検知スタックへの接続方法)
これらのいずれもが、パフォーマンスに大きく影響します。
プロンプトを少し変えただけで、自信満々だった AI アナリストが「PowerShell」の綴りすら忘れてしまうことがあります。
モデルを変えると、レイテンシが倍になることもあります。
MCP の連携を変えると、コンテキストの半分が消えてしまうこともあります。
だからこそ、私たちは再現可能なテストベッドを構築しました。自動評価、実際の SOC シナリオ、そして少しの容赦ない現実を組み合わせたものです。
テストベッド(別名「実際に試してみた」)
最初の検証では、あえてシンプルにしました。Tier-1 タスク、軽度な推論(最大 2 ホップ)、複雑なマルチエージェント構成はなしです。
構成は以下の通りです。
- n8n迅速なプロトタイピングと自動化のため
- Vectra QUX MCPサーバーを使用してデータにアクセスし、プラットフォームを操作
- 最小限のSOCプロンプト(基本的には、「あなたはAIアナリストです。 知らないならそう言ってください」)
- LLMによる評価予想解答と実際の解答の比較
しかし、これはお遊びの実験ではありません。アナリストが日常的に直面する 28 の実際の SOC タスクをテストしました。例えば次のようなものです。
- 高ステータスまたはクリティカルステータスのホストのリスト
- 特定のエンドポイント(piper-desktop、deacon-desktopなど)の検出をプルする。
- IPまたはドメインに結びついたコマンド&コントロール検出のチェック
- 1GB以上の流出を発見
- ホスト・アーティファクトのタグ付けと削除
- “high”または“critical”なリスク象限にある口座を調べる
- EntraID操作に関与する「管理者」アカウントのハンティング
- 特定のJA3フィンガープリントによる検出の照会
- アナリストをホストまたは検出に割り当てる
つまり、忙しい火曜日の朝に Tier-1 や Tier-2 の SOC アナリストが扱うであろう作業のほぼすべてです。
各実行結果は、正確性、速度、トークン使用量、ツール利用状況について 1~5 のスケールで評価しました。
優れた 生成AI エージェントとは何か?
SOC 内で 生成AI を評価する際に重要なのは、どのモデルが賢そうに聞こえるかではありません。どれだけ効率的に考え、行動し、学習するかです。優れた AI エージェントは、鋭いアナリストのように振る舞います。正解を出すだけでなく、効率よくそこに到達します。注目すべきポイントは以下です。
- 効率的なトークンの使用。推論に必要な言葉が少ないほど優れています。冗長なモデルは計算資源とコンテキストを無駄にします。
- スマートなツールコール:同じツールを何度も呼び出すモデルは、「もう一度試させて」と言っているようなものです。優れたモデルは、いつ・どのようにツールを使うべきかを理解し、試行錯誤を最小限に抑え、最大の精度を発揮します。
- 雑さのないスピード:速いことは良いですが、正確性が保たれてこそです。理想的なモデルは、レスポンス性と推論の深さを両立させます。
要するに、最良の AI アナリストは「話す」だけでなく、「効率的に考える」のです。
今回の検証結果は以下の通りです。

主なポイントと実践的な示唆
- GPT-5 は正確性と推論の深さで最も優れていますが、遅くコストが高いです。速度より精度が重要な場合に適しています。
- Claude Sonnet 4.5 は、正確性・速度・効率のバランスが最も優れており、本番 SOC に最適です。
- Claude Haiku 4.5 は迅速なトリアージに最適で、高速・低コストで一次対応には十分な性能です。
- Deepseek 3.1 はコストパフォーマンスに優れ、低コストで印象的な性能を発揮します。
- Grok Code Fast 1 は、オートメーションやエンリッチメントなどツールを多用するワークフロー向けですが、トークン使用量には注意が必要です。
- GPT-4.1……次のシフトには呼ばれない、とだけ言っておきましょう。
そして、良い記事にはグラフが欠かせません 。こちらです。
正確性スコアの比較

技術的には GPT-5 が 4.32/5 でトップですが、正直なところ Claude Sonnet 4.5 と Deepseek 3.1(4.11)はほぼ同等で、違いに気づくことはほとんどないでしょう。本当のどんでん返しは GPT-4.1 で、2.61/5 と大惨事です。これは……セキュリティ用途では使わない方がよいでしょう。
実行時間
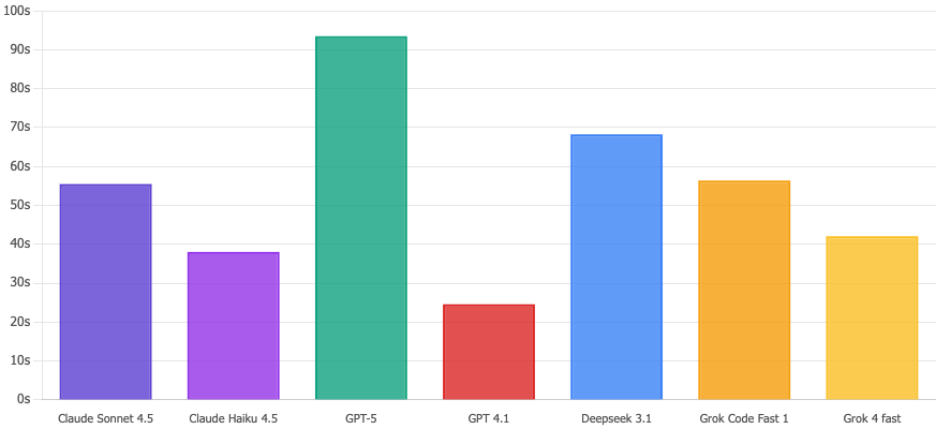
Claude Haiku 4.5 は 38 秒でこれらのクエリを処理します。一方 GPT-5 は 93 秒と、文字通り 2.5 倍遅い結果でした。セキュリティインシデントの可能性がある場面では、その数秒が永遠のように感じられます。Haiku は仕事をやり切ります。
バリュー・プロポジション・マトリックス
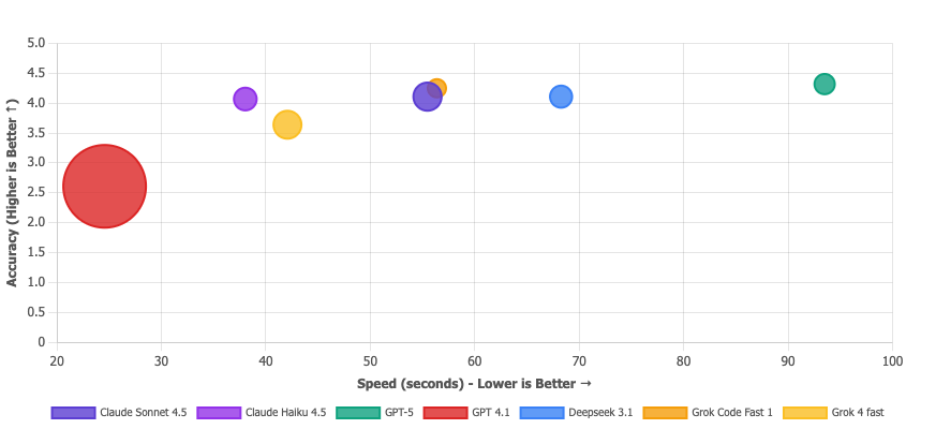
バブルが大きいほど、トークン使用量が少ないことを示します。GPT-4.1 のバブルは巨大ですが、それは自慢にはなりません。テストに失敗しているのに「すごく早く終わった」と言っているようなものです。安くて間違っているのは価値提案ではなく、ただの間違いです。本当に選ぶべきモデルは右上にあります。Deepseek 3.1(効率的かつ正確)、Claude Sonnet 4.5(バランスの取れた強者)、Grok Code Fast(全体的に堅実)。GPT-5 の極小バブルは、高価な選択肢であることを裏付けています。
何を学んだのか?
- 正確性がすべてではありません。わずかに正確でも、処理時間が倍かかり、トークンを 5 倍消費するモデルは最適とは言えません。SOC では、効率とスケールも正確性の一部です。
- ツール利用は推論の窓口です。「単純な質問に答えるのに 10 回もツールを呼び出す LLM は、丁寧なのではなく迷っているのです」。優れたモデルは、正しい答えにたどり着くだけでなく、MCP を通じて 1~2 回の賢いクエリで効率的に到達します。ツール利用は量ではなく、どれだけ早く正しい道筋を見つけられるかが重要です。必ずしも LLM だけが原因とは限りません。最適なツール呼び出しには、優れた MCP サーバーが不可欠です。ただし、MCP の評価はまた別の機会にしましょう。
- プロンプト設計は過小評価されがちです。言い回しをほんの少し変えるだけで、正確性やハルシネーション率が大きく変わります。今回は将来のチューニングに向けたベースラインとして、あえて最小限のプロンプトにしましたが、小さな設計の違いが大きな影響を与えることは明らかです。
まとめ(少しの現実チェック)
結局のところ、大事なのはどのモデルがコンテストで勝つかではありません。確かに GPT-5 が一部の指標で Claude を上回ることはありますが、それは本質ではありません。
本当の教訓は、AI エージェントの評価は「必須」であるということです。
SOC 内で 生成AI に依存するのであれば、アラートのトリアージ、インシデントの要約、さらには封じ込めアクションまで任せる場合、その挙動、失敗するポイント、そして時間とともにどう進化するのかを理解しておく必要があります。
評価のない AI は、説明責任のない自動化に過ぎません。
そして同じくらい重要なのは、セキュリティツールが「LLM の言葉を話せる」ことです。
それは、構造化されたデータ、クリーンな API、機械可読なコンテキストを意味します。ダッシュボードやベンダーのサイロに閉じ込められた情報ではありません。世界で最も高度なモデルであっても、壊れかけのテレメトリを与えられては推論できません。
だからこそ Vectra AI では、プラットフォームと MCP サーバーを設計段階から LLM 対応にすることに徹底的にこだわっています。私たちが生み出すシグナルは、人間のためだけではなく、推論・エンリッチ・アクションを実行できる AI エージェントが利用することを前提に設計されています。
次のセキュリティ運用の波では、AI を使うだけでは不十分です。エコシステム全体が AI 対応である必要があります。
未来の SOC は、単に AI を搭載しているだけではありません。AI によって測定され、AI と接続され、AI に対応しているのです。