

人工知能(AI)の定義は複雑な作業であり、しばしば進化する視点に左右される。目標やタスクに基づく定義は、技術の進歩とともに変化する可能性がある。例えば、IBMのディープ・ブルーが1997年にグランドマスターのゲーリー・カスパロフを破り、チェスに対する認識が知性を必要とするものから総当たり的なテクニックへと変化するまで、チェス対局システムは初期のAI研究の焦点だった。
一方、手続き的あるいは構造的な理由に焦点を当てる傾向のあるAIの定義は、しばしば、心、創発、意識に関する根本的に解決不可能な哲学的な問題に足を取られてしまう。このような定義は、知的システムの構築方法についての理解を深めるものでも、すでに構築されたシステムの説明に役立つものでもない。
チューリング・テスト - 機械の知性を測る尺度

チューリング・テストは、しばしば機械の知能のテストとみなされるが、アラン・チューリングが知能の問題を回避するための方法だった。このテストは、知能の意味論的な曖昧さを強調し、機械にどのようなレッテルを貼るかではなく、機械に何ができるかに焦点を当てた。
「機械は考えることができるか?私は、議論に値しないほど無意味なものだと考えている。とはいえ、今世紀末には、言葉の使い方や一般的な教育者の意見が大きく変わり、反論されることを予期することなく、機械が思考していると語ることができるようになると私は信じている。"- アラン・チューリング
結局のところ、これは慣習の問題であり、潜水艦を「泳ぐ」と呼ぶべきか、飛行機を「飛ぶ」と呼ぶべきかを議論するのと大差はない。チューリングにとって本当に重要なのは、機械の能力の限界であって、その能力をどう呼ぶかではなかった。
AIにおける人間らしい思考の測定
そのため、機械が人間のように考えることができるかどうかを知りたいのであれば、機械が人間のように考えていると他人を欺けるかどうかを測定するのが最善の方法である。チューリングと、1956年に開催されたAIに関する最初のワークショップの主催者が提示した定義に倣い、私たちも同様に、「学習やその他の知能の特徴のあらゆる側面は、原理的に、機械がそれをシミュレートできるように正確に記述することができる」と考えている。
与えられたタスクにおいて人間のようなパフォーマンスや行動を達成するためには、AIはそれを驚くべき精度でシミュレートできなければならない。有名なチューリング・テストは、この能力を評価するために設計されたもので、コンピュータや機械が、構造化されていない会話を通して、観察者をどれだけ効果的に欺くことができるかを評価するものである。チューリングのオリジナルのテストでは、マシンが説得力を持って女性のアイデンティティを描写することまで求められた。
AIの人間レベルの理解力を評価する
近年、機械学習技術の著しい進歩は、豊富な学習データと相まって、アルゴリズムが最小限の理解で会話に参加することを可能にしている。さらに、スペルミスや文法ミスを意図的にランダムに取り入れるなど、一見取るに足らないような戦術が、本物の知性を欠いているにもかかわらず、アルゴリズムがバーチャル・ヒューマンとしての説得力を増している一因となっている。
ウィノグラード・スキーマのような、人間レベルの理解力を評価する新しいアプローチは、人間が一般的に理解している世界、オブジェクトの用途、アフォーダンスに関する知識をマシンに問い合わせることを提案している。例えば、「なぜトロフィーは棚に入らなかったのか?大きすぎたからだ。何が大きすぎたのでしょう?"と聞けば、誰でもすぐにトロフィーが特大の要素であることがわかるだろう。逆に、「トロフィーが棚に収まらなかったのは小さすぎたからだ。何が小さすぎたのでしょうか?
このシナリオでは、答えは明確に棚の中にある。精度を高めたこのテストは、世界に関わる機械知識の深淵を掘り下げる。単純なデータマイニングだけでは答えは得られない。この定義では、AIが人間の行動のあらゆる面をエミュレートする能力を持つことが必要であり、特定のタスクに対して知能を発揮するよう特別に設計されたAIシステムとは意味のある区別がなされる。
AIの種類と学習方法の違い
人工知能(AGI)
人工知能(Artificial General Intelligence:AGI)は、一般的なAIとして知られ、AIに言及する際に最も頻繁に議論される概念である。AGIは、世界を支配する「ロボットの支配者」という未来的な概念を想起させるシステムを包含し、文学や映画を通じて私たちの想像力をかき立てている。
特定または応用AI
この分野の研究のほとんどは、特定の、あるいは応用的なAIシステムに焦点を当てている。これらは、グーグルやフェイスブックの音声認識やコンピュータ・ビジョン・システムから、私たちのチーム(Vectra AI )が開発したサイバーセキュリティAIまで、幅広いアプリケーションを網羅している。
応用システムは通常、多様なアルゴリズムを活用している。ほとんどのアルゴリズムは、時間とともに学習し進化するように設計されており、新しいデータにアクセスするにつれてパフォーマンスを最適化する。新しいインプットに対してレスポンス 、適応して学習する能力は、機械学習の分野を定義している。しかし、すべてのAIシステムがこの能力を必要とするわけではないことに注意することが重要だ。ディープ・ブルーのチェス戦略のように、学習に頼らないアルゴリズムで動作するAIシステムもある。
しかし、このような現象は通常、十分に定義された環境や問題空間に限定される。実際、古典的AI(GOFAI)の柱であるエキスパートシステムは、学習の代わりに、あらかじめプログラムされたルールベースの知識に大きく依存している。AGIは、一般的に適用されるAIタスクの大部分とともに、何らかの機械学習が必要であると考えられている。

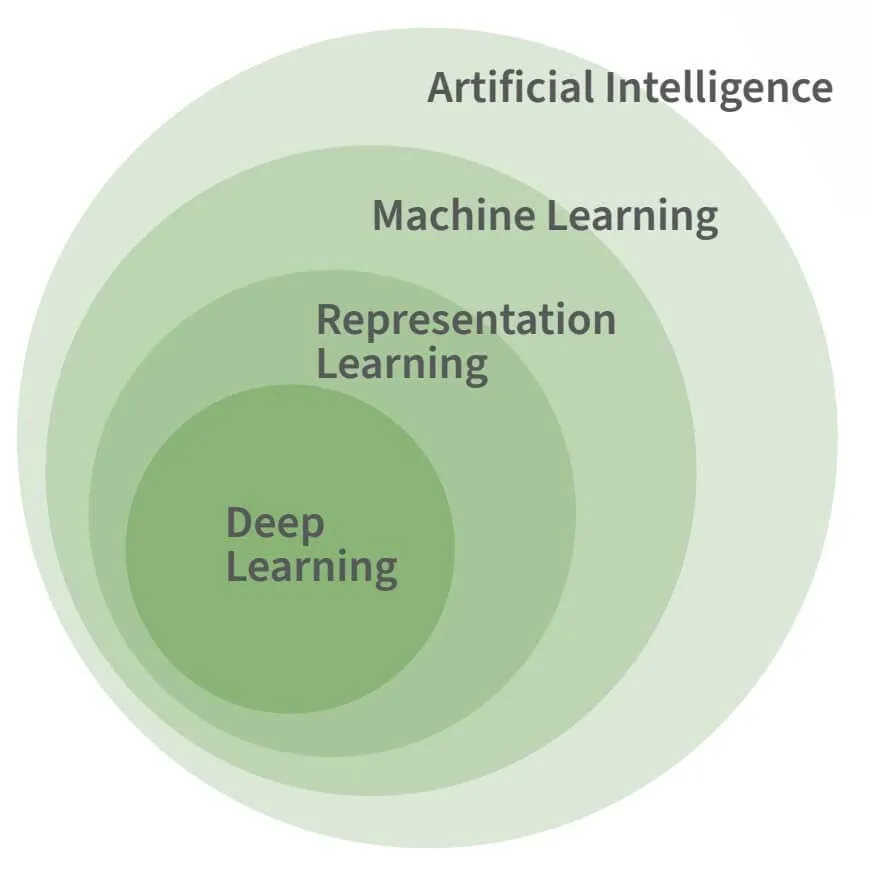
の役割Machine Learning
上図は、AI、機械学習、ディープラーニングの関係を示している。ディープ・ラーニングは機械学習の特殊な形態であり、機械学習はほとんどの高度なAIタスクに必要であると想定されているが、それ自体がAIの必要な、あるいは決定的な特徴というわけではない。
機械学習は、人間の知能の複雑さではなく、基本的な面を模倣するために必要である。例えば、1955年にアレン・ニューウェルとハーバート・サイモンが開発したAIプログラム「Logic Theorist」。このプログラムは、「プリンキピア数学」の最初の52の定理のうち38の定理を、学習の必要なしに証明した。
AI、Machine Learning 、Deep Learning: 何が違うのか?
人工知能 (AI) 、機械学習 (ML) 、深層学習 (DL) は同じものだと混同されがちですが、それぞれ独自の定義を持っています。これらの用語の範囲を理解することで、AIを活用するツールについてより深い洞察を得ることができます。
人工知能 (AI)
AIは、推論を自動化し、人間のマインドに近づけるシステムを包含する広い用語で、ML、RL、DLといった下位分野も含まれます。AIは、明示的にプログラムされたルールに従うシステムだけでなく、データから自律的に理解を得るシステムも指します。データから学習する後者の形態は、自動運転車やバーチャルアシスタントなどの技術の基盤となっています。
機械学習 (ML)
MLはAIの下位分野であり、システムの動作は人間が明示的に指示するのではなく、データから学習されます。MLを使ったシステムは膨大な量のデータを処理し、データの新しいインスタンスに対する最適な表現方法と対応方法を学習することができます。
動画:Machine Learning サイバーセキュリティ専門家のための基礎知識
表現学習 (RL)
RLは見落とされがちですが、現在使われている多くのAI技術にとって極めて重要です。RLはデータから抽象的な表現を学習します。例えば、画像を元の画像の本質を捉えた一貫した長さの数値リストに変換します、この抽象化によって、下流のシステムは新しいタイプのデータをよりうまく処理できるようになるのです。
ディープラーニング (DL)
DL は、より複雑な方法で入力を表す抽象化の階層を発見することにより、ML と RL に基づいて構築されます。 人間の脳からインスピレーションを得た DL モデルは、適応可能なシナプスの重みを持つニューロンの層を使用します。 ネットワークのより深い層は新しい抽象表現を学習し、画像の分類やテキストの翻訳などのタスクを簡素化します。 DL は特定の複雑な問題を解決するのには効果的ですが、インテリジェンスを自動化するための万能のソリューションではないことに注意することが重要です。
参考文献: 「ディープラーニング」、Goodfellow、Bengio、Courville (2016)
AIにおける学習技法
音声を認識したり、画像中の物体を見つけたりするプログラムを作成するのは、人間には比較的簡単に解決できるにもかかわらず、はるかに困難な課題である。この難しさは、人間にとっては直感的に単純なことであるにもかかわらず、音響データから音素、文字、単語を選び出すような単純なルールセットを記述できないことに起因している。これは、ある顔と別の顔を区別する画素の特徴を簡単に定義できないのと同じ理由である。

右の図は、Oliver Selfridgeが1955年に発表した論文「パターン認識と現代のコンピュータ」から引用したもので、同じ入力でも文脈によって異なる出力が得られることを示している。下の図では、THEのHとCATのAは同じピクセル集合だが、HまたはAとして解釈されるのは、文字そのものではなく、周囲の文字に依存している。
このような理由から、解決策を事前に定義しようとするよりも、機械に問題解決の方法を学ばせたほうが成功するのだ。
MLアルゴリズムはデータを異なるカテゴリーに分類します。この能力には、「教師あり学習」と「教師なし学習」という2つの主な学習タイプが大きな役割を果たしています。
教師あり学習
教師あり学習では、ラベル付きデータを使用してモデルを学習し、新しいデータのラベルを予測できるようにします。たとえば、猫と犬の画像を公開したモデルは、新しい画像で猫と犬を分類できます。 ラベル付きトレーニングデータが必要であるにもかかわらず、新しいデータポイントに効果的にラベルを付けることができます。

教師なし学習
教師なし学習はラベル付けされていないデータを扱います。これらのモデルはデータ内のパターンを学習し、新しいデータがそれらのパターンのどこに当てはまるかを判断することができます。教師なし学習は事前の学習を必要としないため、異常を特定することには長けていますが、ラベルを割り当てることは難しいです。
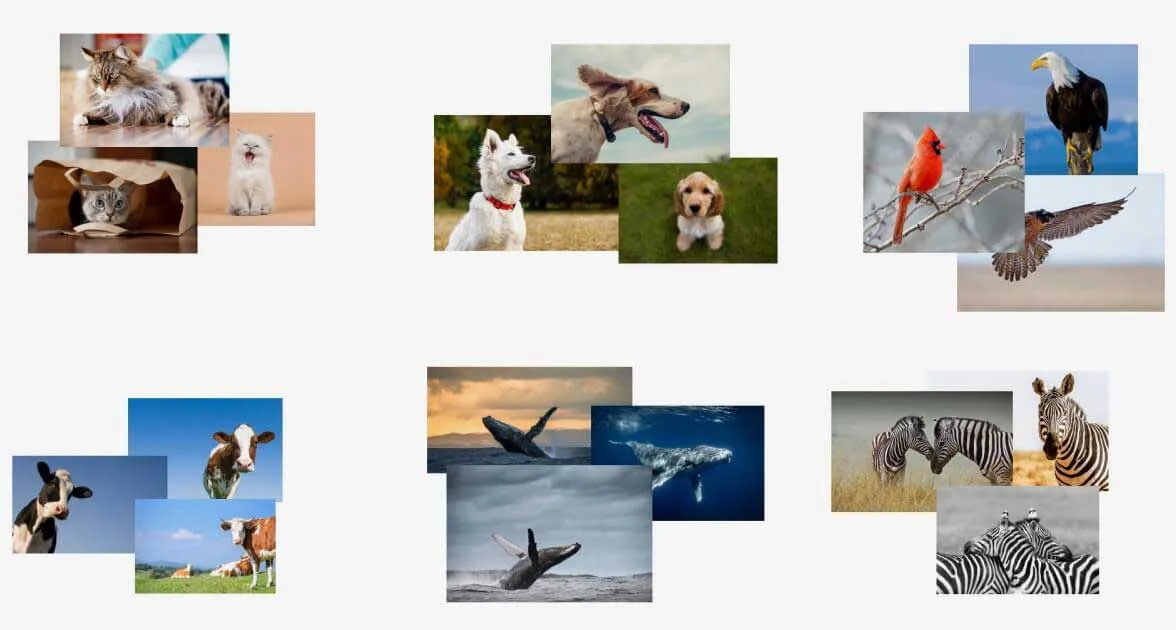
どちらのアプローチも、さまざまな学習アルゴリズムを提供し、研究者が新しいアルゴリズムを開発するに従って常に拡張しています。アルゴリズムを組み合わせることで、より複雑なシステムを構築することもできます。特定の問題に対してどのアルゴリズムを使うべきかを知ることは、データサイエンティストにとっての課題です。どんな問題でも解決できる万能なアルゴリズムというのはあるのでしょうか?

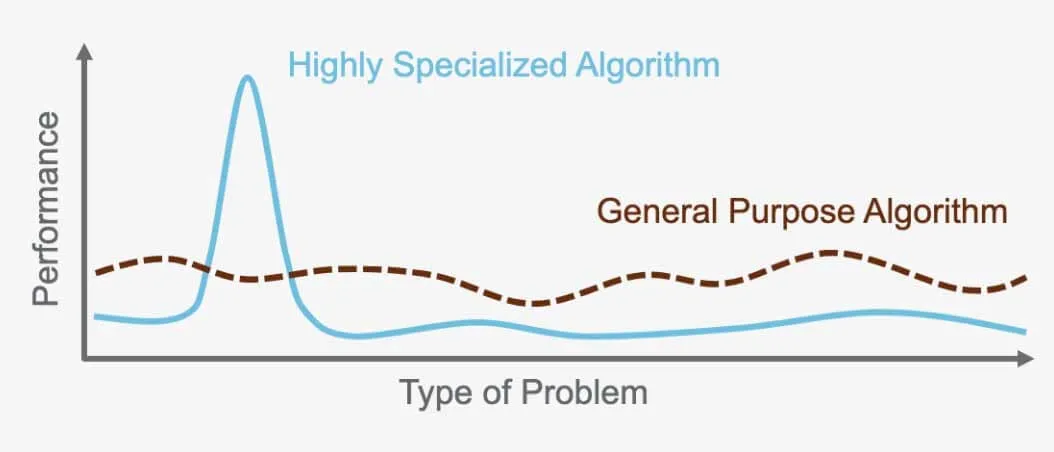
ノーフリーランチ定理:普遍的アルゴリズムは存在しない
「ノーフリーランチ定理」とは、あらゆる問題に対して他のアルゴリズムより優れたパフォーマンスを発揮する完璧なアルゴリズムは存在しないというものです。その代わり、それぞれの問題には、その問題に特化したアルゴリズムが必要になります。これが、非常に多くの異なるアルゴリズムが存在する理由なのです。例えば、教師ありニューラルネットワークは特定の問題に最適ですが、教師なしの階層クラスタリングは他の問題に最適です。各アルゴリズムは、問題と使用されるデータに基づいてパフォーマンスを最適化するように設計されているため、それぞれのタスクに適したアルゴリズムを選択することが重要です。
例えば、自動運転車の画像認識に使われるアルゴリズムは、翻訳には使えません。各アルゴリズムは特定の目的を果たし、それを解決するために作成された問題や操作するデータに合わせて最適化されているのです。
データサイエンスにおける正しいアルゴリズムの選択
データサイエンティストとして正しいアルゴリズムを選択することは、アートとサイエンスの融合です。問題文を検討し、データを徹底的に理解することで、正しい選択ができます。間違った選択をすると、最適でない結果だけでなく、完全に不正確な結果にもつながりかねません。例を見てみましょう。
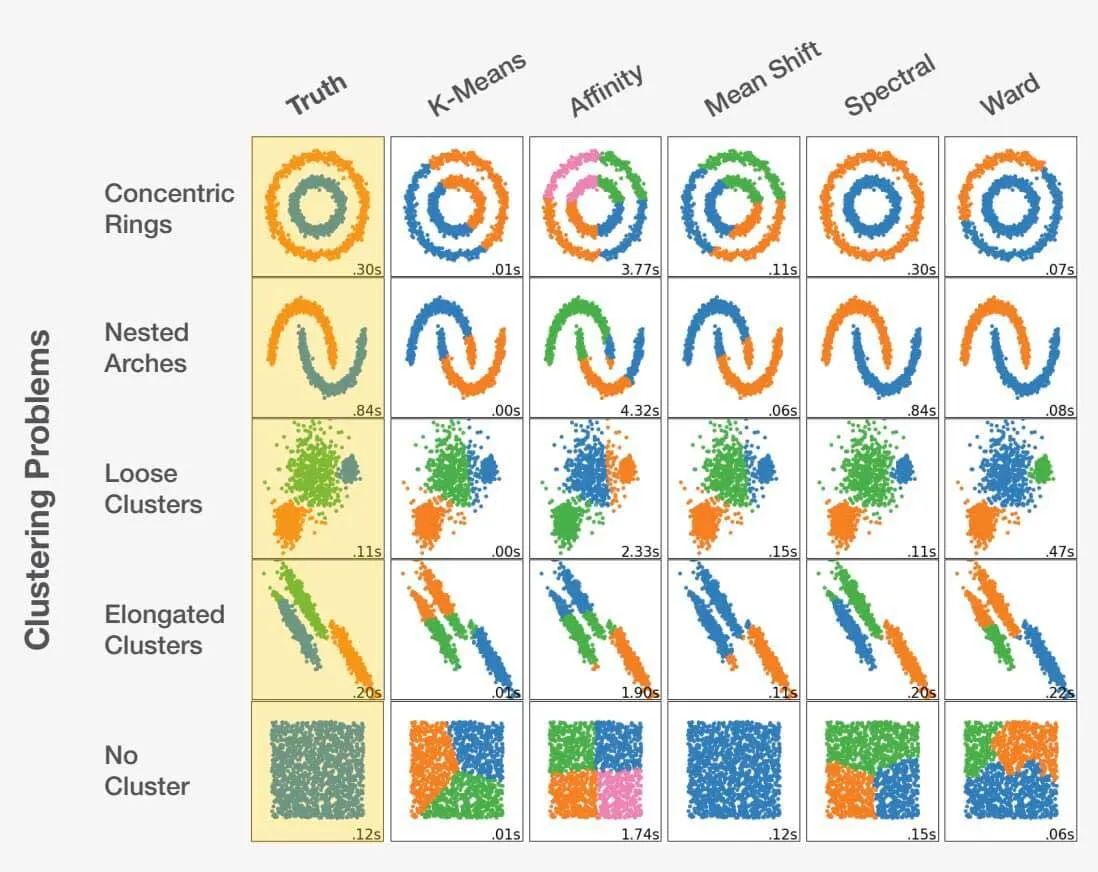
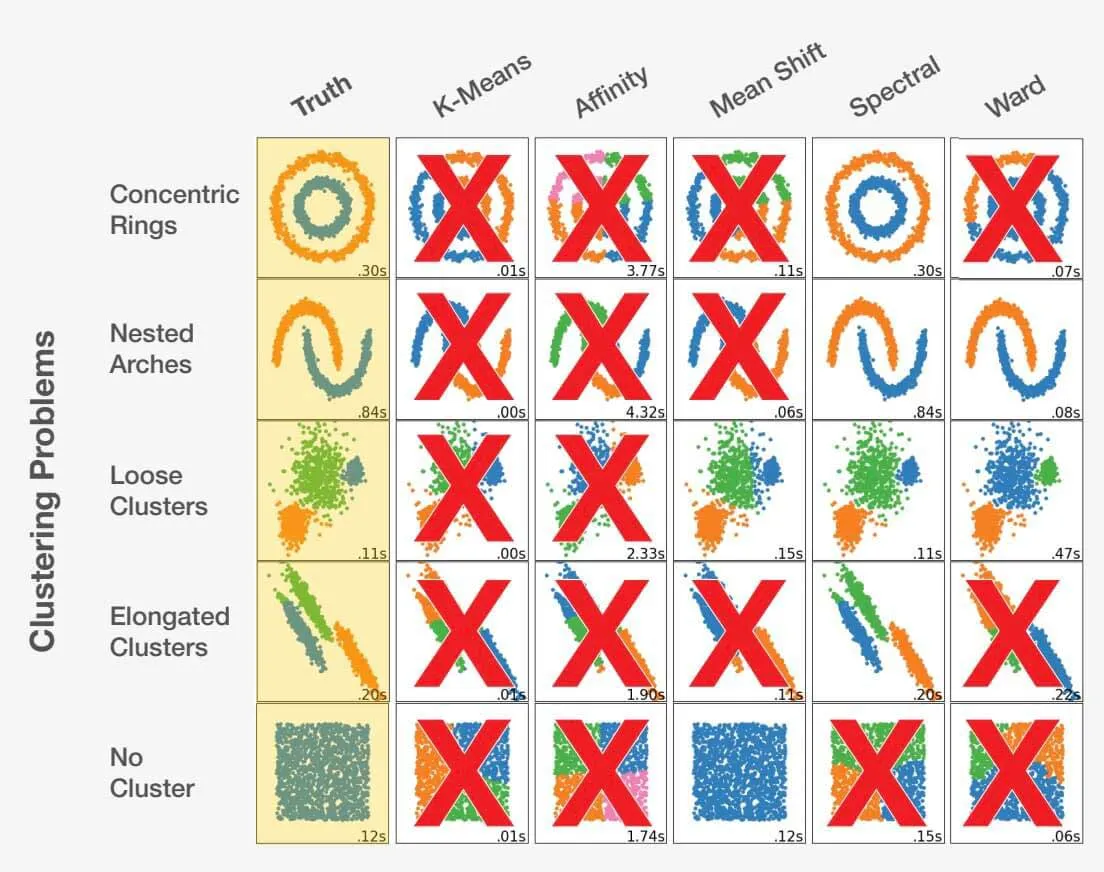
scikit-learn.org.
データセットに適したアルゴリズムを選択することは、得られる結果に大きな影響を与える可能性があります。それぞれの問題には最適なアルゴリズムの選択がありますが、より重要なことは、特定の選択が好ましくない結果につながる可能性があるという点です。特定の問題ごとに適切なアプローチを選択することが重要なのはこのためです。
アルゴリズムの成功を測るには?
データサイエンティストとして適切なモデルを選択することは、正確さだけではありません。精度は重要ですが、モデルの真の性能を隠してしまうこともあります。

2 つのラベル A と B による分類問題を考えてみましょう。ラベル A がラベル B よりも発生する可能性がはるかに高い場合、モデルは常にラベル A を選択することで高い精度を達成できます。ただし、これは、ラベルBとして何かを正しく識別することは決してないことを意味します。 したがって、B のケースを見つけたい場合、精度だけでは十分ではありません。 幸いなことに、データ サイエンティストには、モデルの有効性の最適化と測定に役立つ他のメトリックスがあります。
そのメトリクスの 1 つに精度があります。これは、モデルが特定のラベルを推測する際に、推測の総数と比較してどれだけ正確であるかを測定します。 高精度を目指すデータサイエンティストは、誤検知の生成を回避するモデルを構築します。

しかし、精度は全体の一部にすぎません。 モデルが重要なケースを識別できないかどうかは明らかにされません。 ここで再現率が登場します。再現率は、モデルが特定のラベルをそのラベルのすべてのインスタンスと比較して正しく検知する頻度を測定します。 高い再現率を目指すデータサイエンティストは、重要なインスタンスを見逃さないモデルを構築します。

精度と再現率の両方を追跡し、バランスを取ることで、モデルを効果的に測定し、最適化することができます。