

ランダムフォレストを理解するアンサンブル手法
ランダムフォレスト(RF)モデルは、1995年にTin Kam Hoによって初めて提案された、分類と回帰に適用されるアンサンブル学習法のサブクラスである。アンサンブル法は、分類器の集合(RFの場合は決定木の集合)を構築し、各分類器の出力の加重平均をとることによって、各データ・インスタンスのラベルを決定する。
学習アルゴリズムは分割統治アプローチを利用し、ブートストラップを通じてモデルの単一インスタンスに内在する分散を減少させる。したがって、弱い分類器のグループを「アンサンブル」することで性能が向上し、結果として集約された分類器はより強力なモデルとなります。
ランダム決定森は、2001年にLeo Breimanによって提案されたバギング(bagging - bootstrap aggregating)を改良したもので、ランダムに選択された特徴に関する装飾的な木の大規模なコレクションを集合させる[1]。森を構成する木の ``数`` はモデルの分散に関係し、木の ``深さ`` または ``各木が構成されるノードの最大数`` はモデルに存在する還元できないバイアスに関係する。

RFには多くの利点がある:実装と実行が非常に速く(大規模データセットで効率的に実行される)、最も正確な学習アルゴリズムの1つであり、オーバーフィッティングや外れ値に強い[2]。RFの性能は、樹木アンサンブル手法のもう1つのサブクラスである勾配ブースト決定木(GBDT)と似ているが、より頑健である。さらに、RFはGBDTよりもハイパーパラメータが少ないため、学習や調整が容易である。その結果、RFは非常に人気があり、RやSASのようなさまざまな言語や、scikit-learnやTensorFlowを含むPythonの多くのパッケージでサポートされている。
TensorForestエスティメータ:互換性と使用法
TensorFlowは最近、tensor_forestというモジュール(https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/tensor_forest/__init__.py で定義されている。TensorFlow公式サイトのtensor_forestへのリンクは、masterブランチではなく、最新バージョンのブランチにユーザを誘導することに注意) を通じて、RFのサポートを貢献コードベース (tf.contrib) に追加した。バージョン1.3.0では、バージョン1.2.0からtensor_forestに大きな変更が加えられており、これから説明するコード構造とパラメータはバージョン1.2.0に準拠しています。
TensorForestの構造と実装
tensor_forestを使うには、以下のモジュールをインポートする必要がある:
- fromtensorflow.contrib.learn.python.learnimportmetric_spec
- fromtensorflow.contrib.learn.python.learn.estimatorsimportestimator
- fromtensorflow.contrib.tensor_forest.clientimporteval_metrics
- fromtensorflow.contrib.tensor_forest.clientimportrandom_forest
- fromtensorflow.contrib.tensor_forest.pythonimporttensor_forest
TensorFlowでRFを実行する最初のステップは、モデルを構築することである。RF推定器を構築するには、まずRFのハイパーパラメータを以下のように指定する:
hparams = tensor_forest.ForestHParams(num_classes=NUM_CLASSES,num_features=NUM_FEATURES,num_trees=NUM_TREES,max_nodes=MAX_NODES,min_split_samples=MIN_NODE_SIZE).fill()上述したテンソルフォレストの各ハイパーパラメータを以下に説明する:
num_classes``:ラベルのクラス数
num_features``:特徴の数。num_splits_to_consider`` または ``num_features`` のいずれかを指定する。
tensor_forestのコード作成者によれば、このモデルはより正確である。
when ``num_splits_to_consider`` == ``num_features``[4].
num_trees``:最頻値[分類の場合]または平均値[分類の場合]を求めるために構築する木の本数。
予測値の回帰]。樹木は「ノイズが多いことで有名」であるため、「平均化から大きな恩恵を受ける」[5]。森を構成する樹木が多ければ多いほど、モデルの分散は小さくなり、したがって結果はより正確になる。しかし、出力性能と実行速度はトレードオフの関係にある。多数の木を使用することは、より多くの計算コストを意味し、コードを著しく遅くする可能性がある。通常、ツリーの数が一定数を超えると、モデルの性能は頭打ちになり、改善はごくわずかです[6]。
私は、デバッグのために自分のコードをテストするために5本の森を作り、精度、正確さ、リコール、aucなどの最初の感触を得るために100本の森を作り、大きな調整を必要としない最終的なモデルのために500本の森を作るのが好きだ。一般的に、1000ツリーのモデルを使っても、500ツリーの森からパフォーマンスが大幅に向上することはない。
*デフォルト:100
以下の2つのハイパーパラメータは、フォレスト内の木の深さを決定する。木の深さを制限することは、計算時間を制限する以外に何の追加ボーナスも与えないので、推奨されない[7]。深さが大きいほどバイアスは小さくなる。木が「十分に深く成長すると、バイアスは比較的小さくなる」[8]。
``max_nodes``:各ツリーで許可されるノードの最大数。max_nodes`` を大きくすると
木が深くなる。
*デフォルト:10000
min_split_samples``:"内部ノードを分割するのに必要な最小サンプル数" による。
SKlearn[9].min_split_samples``は最小ノードサイズに関連している。ノードを分割するのに必要なサンプル数が少ないほど、木は深く成長することができる。
*デフォルト:5

次に、RFで使用するグラフの種類を決定する:デフォルトの RF グラフ [``RandomForestGraphs``] と学習損失グラフ [``TrainingLossForest``][11] である。事前学習では、重みベクトルを渡すことで、アンバランスなデータセットに対して正のインスタンスを重み付けすることができる。
[注: ``SKCompat`` はTensorFlow[12]のscikit-learnラッパーである。model_dir`` には、RFとtensorboard可視化用のログファイルを保存するディレクトリを指定する。]
RFグラフを選択した場合:
アップウェイトを指定する:
graph_builder_class = tensor_forest.RandomForestGraphs
est = estimator.SKCompat(random_forest.TensorForestEstimator()
params、
graph_builder_class=graph_builder_class、
model_dir=MODEL_DIRECTORY、
weights_name='ウェイト'))
または、プラスとマイナスのデータポイントの重み付けをデフォルトの1対1のままにしておく:
graph_builder_class = tensor_forest.RandomForestGraphs
est = estimator.SKCompat(random_forest.TensorForestEstimator()
params、
graph_builder_class=graph_builder_class、
model_dir=MODEL_DIRECTORY))
学習損失フォレストの場合、デフォルトの損失関数[``log_loss``]または指定された損失関数から計算された学習損失が重みの調整に使用される[13]。
損失関数としてデフォルトの ``log loss`` を使用する:
graph_builder_class = tensor_forest.TrainingLossForest
または、学習損失グラフで使用する損失関数を指定する[14]:
fromtensorflow.contrib.losses.python.lossesimportloss_ops
# 有効な損失関数は以下の通りである:
#["absolute_difference"、
#"add_loss"、
#"cosine_distance"、
#"compute_weighted_loss"、
#"get_losses"、
#"get_regularization_losses"、
#"get_total_loss"、
#"hinge_loss"、
#"log_loss"、
#"mean_pairwise_squared_error"、
#"mean_squared_error"、
#シグモイドクロスエントロピー」、
#"softmax_cross_entropy"、
#sparse_softmax_cross_entropy"]]。
def loss_fn(val, pred):
ロス = ロス_ops.hinging_lss(val, pred)
リターン・ロス
def _build_graph(params, **kwargs):
return tensor_forest.TrainingLossForest(params、
loss_fn=_loss_fn, **kwargs)
graph_builder_class = _build_graph
最後に、先に指定したハイパーパラメータとグラフを用いてRF推定量を構築する。 est= estimator.SKCompat(random_forest.TensorForestEstimator(
hparams、
graph_builder_class=graph_builder_class、
model_dir=MODEL_DIRECTORY))
RFが構築されたら、``fit``メソッドを使ってモデルをトレーニングデータにフィットさせる。
アップウェイトが指定されたRFグラフの場合*:
est.fit(x={‘x’:x_train, ‘weights’:train_weights},
y={‘y’:y_train},
batch_size=BATCH_SIZE、
max_steps=MAX_STEPS)
*注意:`weights` は先ほどの ``TensorForestEstimator`` に渡されたものと同じキーでなければならない。
train_weights``は次元: (サンプル数, )でなければならない。
デフォルトの1対1のウェイト、またはトレーニングロスの森の場合:
est.fit(x=x_train, y=y_train)
batch_size=BATCH_SIZE、
max_steps=MAX_STEPS)
モデルによって出力された結果を評価するには、必要なメトリクスを特定し、それらを ``evaluate`` 関数に渡します[15]。
# その他の指標は以下の通り:
# 真陽性:tf.contrib.metrics.streaming_true_positives
# 真の否定:tf.contrib.metrics.streaming_true_negatives
# 偽陽性: tf.contrib.metrics.streaming_false_positives
# 偽陰性: tf.contrib.metrics.streaming_false_negatives
# auc: tf.contrib.metrics.streaming_auc
# r2: eval_metrics.get_metric('r2')
# precision: eval_metrics.get_metric('precision')
# recall: eval_metrics.get_metric('recall')
metric = {‘accuracy’:metric_spec.MetricSpec(eval_metris.get_metric(‘accuracy’),
prediction_key=eval_metrics.get_prediction_key('accuracy')}。
アップウェイトが与えられた場合:
model_stats = est.score(x={‘x’:x_test, ‘weights’:test_weights},
y={‘y’:y_test},
batch_size=BATCH_SIZE、
max_steps=MAX_STEPS、
metrics=metric)
for metric in model_stats:
print('%s: %s' % (metric, model_stats[metric])
デフォルトの重み付けとトレーニングロス・フォレスト用:
model_stats = est.score(x=x_test, y=y_test)
batch_size=BATCH_SIZE、
max_steps=MAX_STEPS、
metrics=metric)
for metric in model_stats:
print('%s: %0.4f' % (metric, model_stats[metric])
各データ・インスタンスの各クラスの予測ラベルと確率について:
[注:``predicted_prob``と``predicted_class``は、元の入力の順序を保持するnumpy配列である。]
アップウェイト指定:
predictions = dict(est.predict({‘x’:x_test, ‘weights’:test_weights}))
predicted_prob = predictions[eval_metrics.INFERENCE_PROB_NAME].
predicted_class = predictions[eval_metrics.INFERENCE_PRED_NAME].
デフォルトの重み付けとトレーニングロス・フォレスト:
predictions = dict(est.predict(x=x_test))
predicted_prob = predictions[eval_metrics.INFERENCE_PROB_NAME].
predicted_class = predictions[eval_metrics.INFERENCE_PRED_NAME].
最後に、ターミナルからtensorboardを立ち上げて、トレーニングプロセスとTensorFlowグラフを可視化する:
前に ``model_dir`` に渡したディレクトリを指定する。
$ tensorboard --logdir="./"
http://localhost:6006/、または上記のコマンドを実行したときのリンクをブラウザで開き、tensorboardを表示する。

ランダムフォレストモデルにおけるTensorFlowとScikit-Learnの比較
現在、TensorFlowとscikit-learnはどちらも非常に人気のあるパッケージであり、それぞれ専門家チームがコードベースを寄稿・管理しており、コードの使い方に関する無数のチュートリアルがオンラインや印刷物で提供され、ほとんどの機械学習アルゴリズムをカバーしている。しかし、これら2つのモジュールは同じタスクを対象としているわけではない。
スキキット学習

Scikitは、長い間「事実上の公式Python一般機械学習フレームワーク」とみなされてきた[17]。分類、回帰、クラスタリング、次元削減など、さまざまなカテゴリに属する機械学習アルゴリズムの包括的なコードベースを提供している[18]。これらのよくパッケージ化されたアルゴリズムにより、ユーザはデータセットの分析を簡単かつ迅速に行うことができる。一例として、sklearn には数行でデータセットに導入できる RF モジュールが含まれている:

scikit-learnは、その使いやすさと標準化されたAPIに加えて、ドキュメントも非常に充実している。各ライブラリについて、インターフェース、入力パラメータ、出力フォーマットの詳細だけでなく、入念に構築された例でコードの使い方を示すことに特化したページがあります。sklearnのRFモジュールを再び具体的な例として使う:
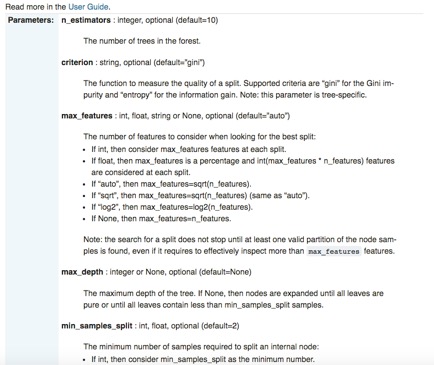

scikit-learnは、「構文が簡潔」[22]であるなど、数多くの顕著な長所を持っていますが、1つの特別な欠点があります:sklearnはGPUをサポートしていませんし、近い将来サポートする予定もありません[23]。「GPUのサポートは、多くのソフトウェア依存性を導入し、プラットフォーム固有の問題を引き起こすでしょう。[ニューラルネットワーク以外では、GPUは今日の機械学習で大きな役割を果たしていない」とsklearnの公式ウェブサイトは述べている。一方、TensorFlowのGPUネイティブ・サポートは、特にディープラーニングに適している。
テンソルフロー
TensorFlowの威力は、「GPU[や]場合によっては複数のマシンのクラスタ上でディープニューラルネットワークをトレーニング[する]」[24]ことができるスケーラビリティと、独自のディープラーニングアルゴリズムを組み立てる際にユーザーに与えられる自由度の高さにある。ユーザーは、どのようなモデルを利用するかだけでなく、フレームワークが提供するプリミティブを使って、どのように実装するかも指定する[25]。どのように[...]データを変換すべきか[そして]どのような損失関数をモデルが最適化すべきか」を正確に定義するのである[26]。加えて、TensorFlowは非常に柔軟で移植性が高く、Ubuntu、Mac OS X、Windows、Android、iOSを含む広範なプラットフォームと、Python、Java、C、Go[27]などのさまざまな言語で利用可能である。TensorFlowは、スケーラビリティと統合性で特に魅力的に見えるが、複雑なコード構造、謎めいたエラーメッセージ、そして、場合によっては、不十分なドキュメント化されたモジュールは、デバッグプロセスに過度の負担をかける。したがって、「ほとんどの実用的な機械学習タスク」にTensorFlowを利用するのは、おそらくやりすぎだ[28]。
Scikit Flowの紹介:TensorFlowとScikit-Learnの橋渡し
[https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/learn/python/learn]
Scikit flow (SKFlow)は、scikit-TensorFlowのジレンマに対するソリューションとして導入された。これは「scikit-learnの構文の簡潔さを利用することで、TensorFlowのモデリング能力」を利用するものである[29]。SKFlowはGoogleによって開発された公式プロジェクトであり、TensorFlowの簡略化された高レベルラッパーを提供する[30]。
SKFlowでは、それぞれ10、20、10個の隠れユニットを持つ3層のニューラルネットワークを4行で実装できる:

あるいは、SKFlowを使って10行程度のコードでカスタムモデルを構築することもできる:
